Ensemble Perception

We frequently encounter crowds of faces. Here we report that, when presented with a group of faces, observers quickly and automatically extract information about the mean emotion in the group. This occurs even when observers cannot report anything about the individual identities that comprise the group. The results reveal an efficient and powerful mechanism that allows the visual system to extract summary statistics from a broad range of visual stimuli, including faces.
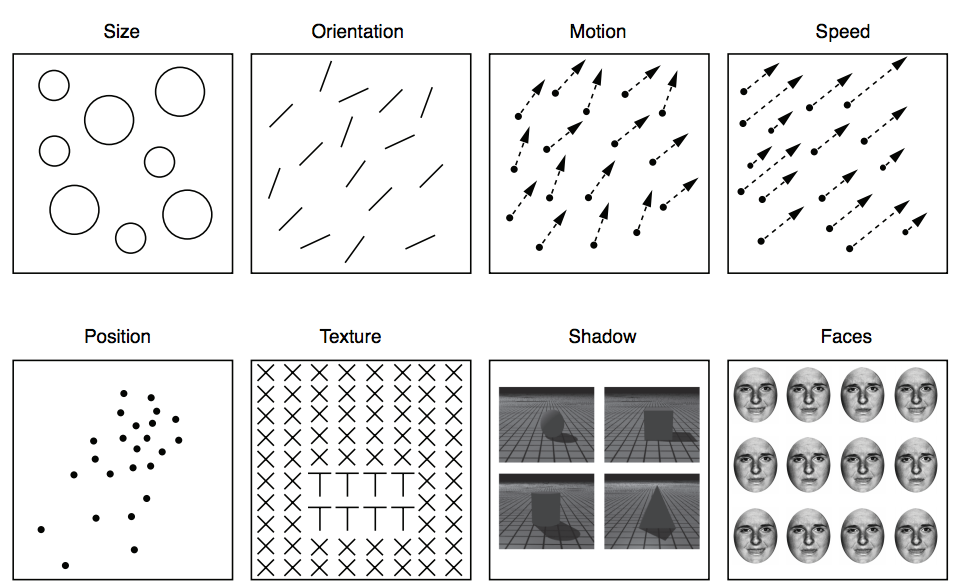
From Whitney and Haberman (2011). These represent some of the various domains in which summary statistical representation occurs. The flexibility of summary representation suggests that it occurs across multiple levels along the visual hierarchy.


Within faces, summary statistical representation can occur for emotions (as in the top image) or for identity (as in the bottom image), as well as gender, ethnicity, and direction of gaze. This, again, demonstrates the flexibility of summary representation.

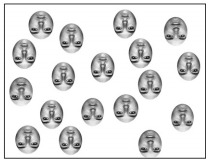
The summary representation effect also occurs for inverted faces. But not very well. Upright face summaries are special.
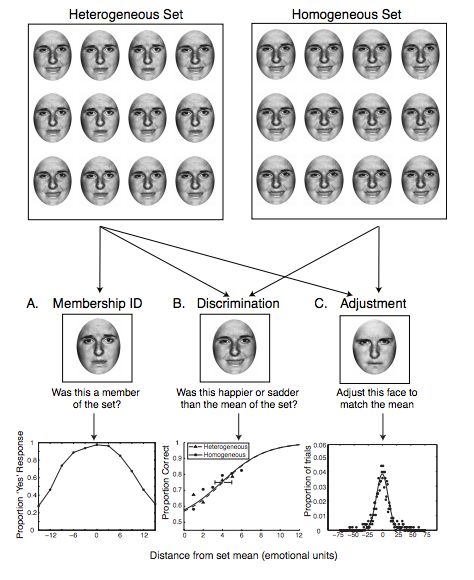
From Whitney and Haberman (2011). Faces - Observers were presented with either a heterogenous or homogenous set of faces. Observers were asked to identify whether a test face had been a member of the previously displayed set; observers were most likely to indicate a test face was a set member when it approached the mean expression. Thus, observers were unable to represent the individual set constituents, but instead favored the ensemble. Observers were also asked about the average expression in a set. They could discriminate the mean expression as well as discriminate any single face. Observers were also asked to adjust a test face to the mean expression of the set. This provided the full error distribution of the mean representation. Responses tended to cluster around the mean expression of the set.
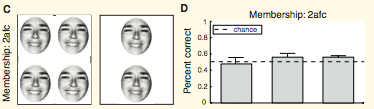
From From Whitney and Haberman (Current Biology, 2007) . Observers are at chance when indicating which of two test faces was a member of the preceding set, suggesting that we don't retain any information about the set's individual identities. (The target here was the top face). This is remarkable considering that we appear to be very good at extracting the mean emotion from a set of faces. So, even though we may not process each face individually, we are very good at processing a whole crowd.
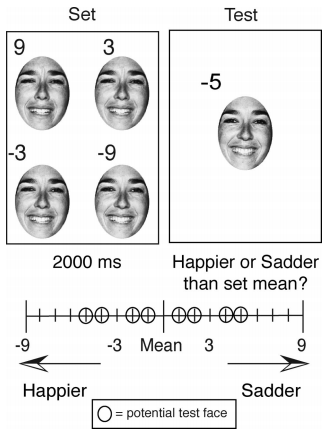
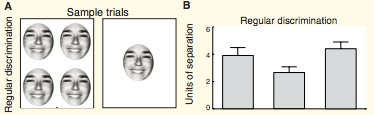
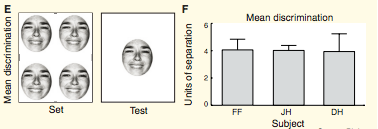
From Whitney and Haberman (Current Biology, 2007) and Whitney and Haberman (Journal of Experimental Psychology, 2009) . Observers were asked to indicate whether a test face was happier or sadder than the mean emotion of the preceding set. The test face could be any distance away from the mean as indicated by the emotion meter in this image. To discriminate whether a test face was happier or sadder than a previously viewed set of faces with 75% accuracy, the test face had to be 3-4 units happier or sadder than the set. In the example set A, the test face is 6 units happier than the set. Observers had a remarkably precise representation of the mean emotion of a set. Their 75% correct discrimination of the mean emotion of the set was almost as precise as their ability to discriminate two faces that displayed different emotions - compare the two bar graphs. In the example set E, the test face is 4 units sadder than the mean emotion of the set. The error bars in both graphs indicate a 95% confidence interval.
Ensemble Coding Crowds in Multiple Viewpoints

From Leib, Fisher, Liu, Qui, Robertson, and Whitney (Journal of Vision, 2014) . Natural scenes contain objects and people arranged in diverse orientations. Does statistical summary operate successfully across these 3D, viewpoint-invariant representations? We investigated this question by showing participants faces rotated in different orientations (see video at left). After participants viewed the display, we asked them to judge the average identity of the crowd using a method-of-adjustment test. Importantly, a correct response requires participants to incorporate faces from multiple viewpoints into a unified ensemble percept. Our results show that participants accurately perceived the average identity of the crowd—even when the faces were displayed in different orientations. Control conditions confirmed that participants were truly engaging in ensemble coding behavior-- and not merely sampling a subset of faces. Participants were more precise at estimating the average identity of the crowd, compared to discriminating a single face. We also found that participants achieved the ensemble percept more quickly than individuating, attentionally dwelling upon, or mentally rotating a face. These results broadened applicability for ensemble coding in natural, heterogeneously-oriented scenes.
Ensemble Coding Crowd Identity with Faceblindness
From Leib, Puri, Fischer, Bentin, Whitney, and Robertson (Neuropsychologia, 2012) . People with face blindness, or prosopagnosia, commonly report that scanning crowds is challenging. Can prosopagnosics’ discomfort with crowds be explained entirely by their deficits in perceiving single faces? Or could it reflect a more general impairment in integrating and extracting face-related information from the crowd as a whole? We tested prosopagnosics in both standardized face recognition tasks and a statistical summary task. Specifically, in the standardized face recognition task, prosopagnosics were asked to recognize the identity of one face, whereas in the statistical summary task prosopagnosics were asked to determine the average identity of a crowd of faces, using the method of adjustment approach. As expected, prosopagnosics performed worse than controls on all standardized individual face recognition tasks. However, interestingly, prosopagnosics performed remarkably well on the statistically summary task, exhibiting performance similar to controls. Consistent with previous research, our results suggest that ensemble coding processes are distinct from single face individuation processes. Our results also may suggest that ensemble coding can serve as a compensatory mechanism under uniquely impoverished conditions.